

2022年9月2日
人事のためのデータ分析入門:クラスター分析 ~社員をタイプ分けする手法~(セミナーレポート)
ビジネスリサーチラボは、2022年7月にセミナー「人事のためのデータ分析入門:クラスター分析 ~社員をタイプ分けする手法~」を開催しました。
企業には様々な社員が在籍していますが、あらゆる施策で個別対応をとるのは現実的とは言えません。その中で有効といえるのが社員の「タイプ分け」です。タイプに基づき施策を分けることで、機能しやすくなります。
本コラムでは、タイプ分けをデータに沿って実現する「クラスター分析」を取り上げて、ビジネスリサーチラボ・フェローの能渡真澄が、分析の具体的な進め方を解説し、代表取締役の伊達洋駆が、現場で実用することでもたらされる意義を紹介します。
※本レポートはセミナーの内容を基に編集・再構成したものです

登壇者
 伊達洋駆:株式会社ビジネスリサーチラボ 代表取締役
伊達洋駆:株式会社ビジネスリサーチラボ 代表取締役
神戸大学大学院経営学研究科 博士前期課程修了。修士(経営学)。2009年にLLPビジネスリサーチラボ、2011年に株式会社ビジネスリサーチラボを創業。以降、組織・人事領域を中心に、民間企業を対象にした調査・コンサルティング事業を展開。研究知と実践知の両方を活用した「アカデミックリサーチ」をコンセプトに、組織サーベイや人事データ分析のサービスを提供している。著書に『現場でよくある課題への処方箋 人と組織の行動科学』(すばる舎)や『越境学習入門 組織を強くする「冒険人材」の育て方』(共著;日本能率協会マネジメントセンター)などがある。
 能渡真澄:株式会社ビジネスリサーチラボ フェロー
能渡真澄:株式会社ビジネスリサーチラボ フェロー
信州大学人文学部卒業,信州大学大学院人文科学研究科修士課程修了。修士(文学)。価値観の多様化が進む現代における個人のアイデンティティや自己意識の在り方を、他者との相互作用や対人関係の変容から明らかにする理論研究や実証研究を行っている。高いデータ解析技術を有しており、通常では捉えることが困難な、様々なデータの背後にある特徴や関係性を分析・可視化し、その実態を把握する支援を行っている。
得点の「距離」によるタイプ分け[1]
能渡:
ビジネスリサーチラボのフェローの能渡と申します。ビジネスリサーチラボでは、データ分析や調査設計を専門として携わっています。
まず、サーベイの回答データで、どのようにタイプ分けが可能になっていくのかを紹介していきます。タイプ分けとは簡単に言うと、何らかの基準で似ている人たちをグループに分けることです。
これを、組織サーベイの例に置き換えると、各指標への回答が似ている人同士をグループに分けることで、タイプ分けができるのです。ここで注目したいのは、下図に示すように、回答が似ている人たちは、データ間の距離が短いという特徴です。

例えば、指標A・Bについて、両方とも得点が高いAさんとCさんを仮定し、右側のグラフで点をプロットしてみると、他の回答者との距離に比べて、とても近い位置にいることがわかります。同じように、回答が両方とも低いBさんとFさんも、他の人たちとの距離に比べて、短い所にそれぞれデータがプロットされます。
データ分析でいうと、回答が似ているというのは、距離が近いということなんですね。この話を逆に追っていくと、データの距離が短い人は、回答が似ている人なので、同じタイプだとみなせるわけです。クラスター分析は、この考え方を基にタイプ分けを行います。
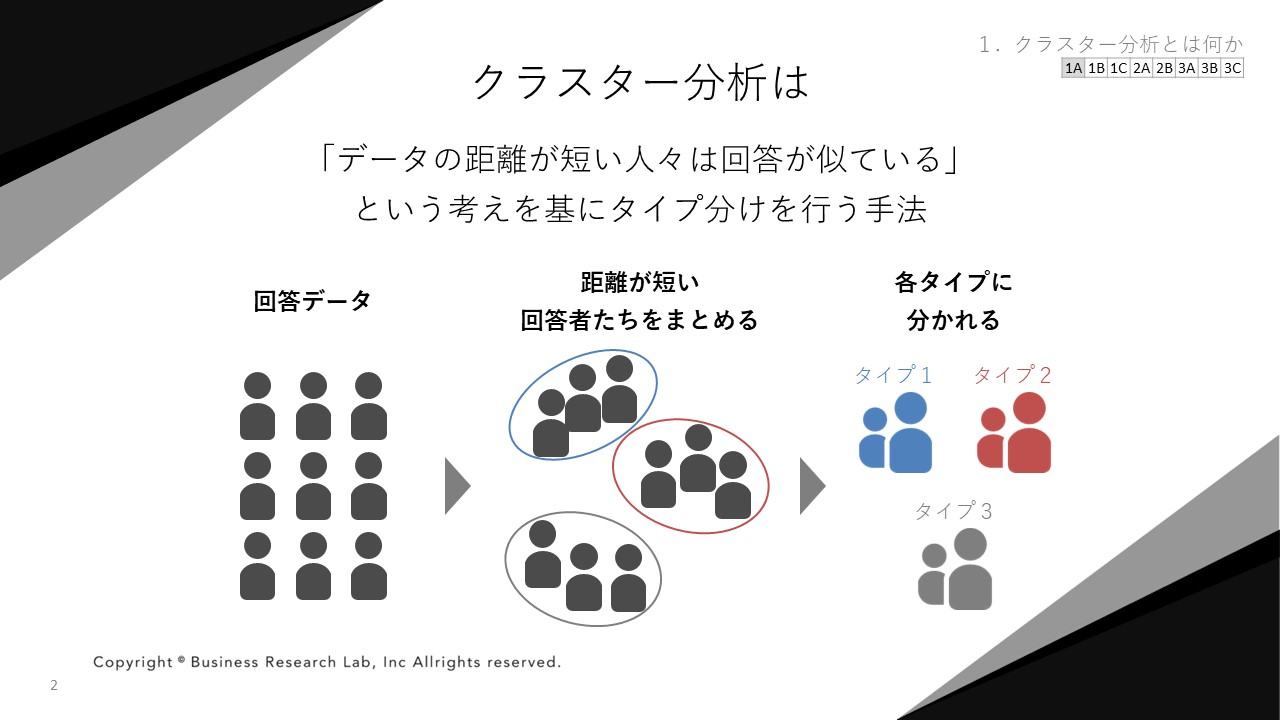
クラスター分析の大きな特徴は、複数の指標を用いたタイプ分けを、データに基づいて構成できる点にあります。例えば、5つの指標を200人に回答してもらい、そのデータを分析にかければ、全ての回答を踏まえて複数のタイプを構成できます。

分析結果を左右する基準「デンドログラム」
デンドログラムが意味する内容
以降、クラスター分析に関して細かく説明をしていきますが、クラスターとクラスタリングという二つの用語を押さえておきましょう。
クラスター:回答者のまとまりや、グループそのもの
クラスタリング:回答者をまとめていくこと
クラスター分析では、分析に含めた様々な指標への回答データから回答者間の距離を算出し、その距離が近い順にクラスタリングをしていきます。クラスタリングの中でクラスターがまとまっていき、最終的にクラスターが一つにまとまるまで続けられます。
ここで問題となるのが、クラスタリングをいつ終えればよいのかです。
クラスターが一つにまとまってしまってはタイプ分けも何もなくなります。その手前の二つ、三つあるいは四つがいいのか判断が必要です。そして、それを分析者自身が決めなくてはならない点が悩みどころです。
クラスターの個数を考えるためにデンドログラムを確認する方法があります。デンドログラムとは、クラスタリングの過程がグラフ化されたもので、トーナメント表のような形で出力されます(下右図)。
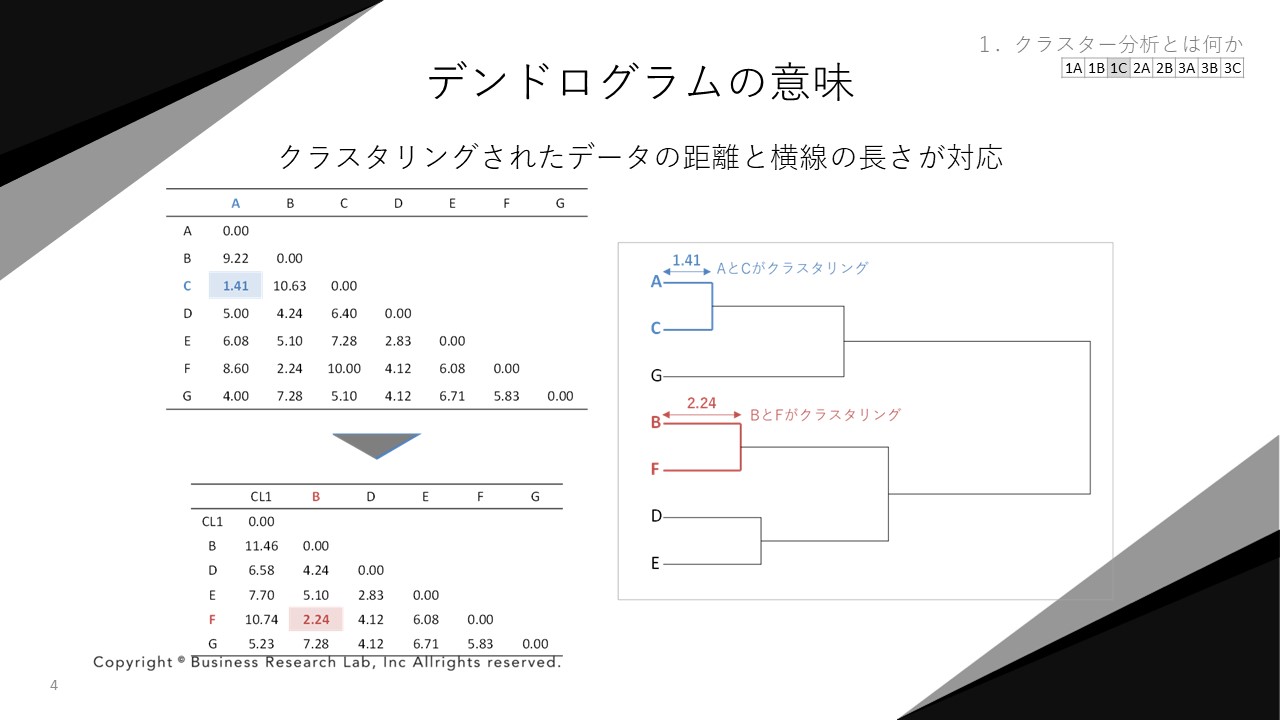
先ほど触れた回答者間の距離のデータと、デンドログラムの横軸の長さが対応しています。例えば、上記右側の図では、AとCが最初に一つにまとまっています。これは、上記左側の表に示したデータ間の距離に対応しています。A・Cのデータ間の距離が一番短いため、この2つが最初にクラスタリングされるのです。
AとCがクラスタリングされたら、そのクラスターと他の回答者間の距離が再計算されて次のクラスタリングを行います。すると、次にもっとも距離が短いのはB・Fのデータなので、この2つが次にクラスタリングされます。
このように、デンドログラムはどの回答者がクラスタリングされていったかを可視化しており、横線の長さはデータ間の距離の長さと対応しています。つまり、横線が長いほど回答者間の距離が長く、一つのクラスターにクラスタリングされるまでの距離も長いことを表しているのです。
このように、回答者間の距離の情報に基づいて、どの回答者同士が順にクラスタリングされていったのかを可視化したものがデンドログラムとなります。
デンドログラムの活用方法
デンドログラムを用いてクラスターの判断を行う方法として、一番右側の横線を除き、次のクラスタリングまでの横線がより長くなった箇所を確認するものがあります。
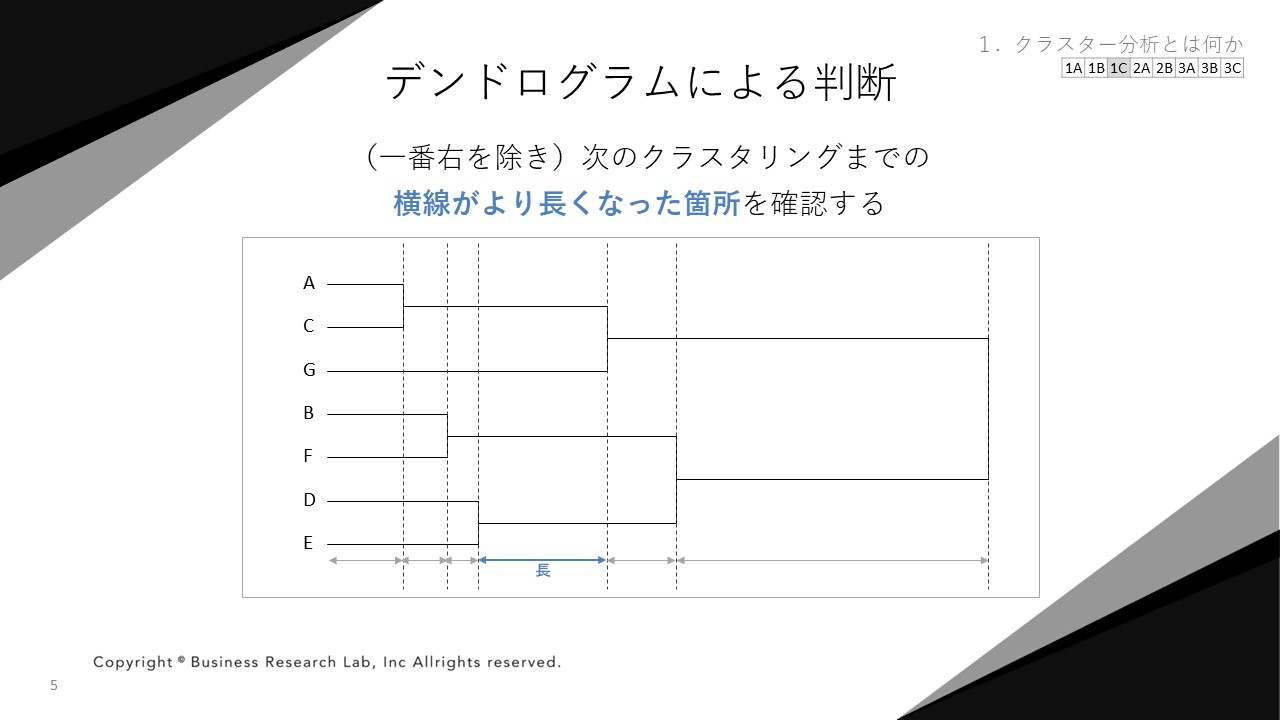
仮に、上図のような結果が得られたとします。横線の長さを見ると、A・CのクラスターとGがクラスタリングされるまでの距離は、ほかと比べて長いことがわかります。
なぜ、横線が長い箇所に着目するのでしょうか。先程述べたように、横線が長い箇所は、クラスタリングまでにかかっている距離が長いことを意味しているからです。
クラスタリングの距離が短ければ短いほど、回答者間の距離が短いことを表し、距離が近い回答者同士のデータは似ています。逆に言えば、デンドログラムにおける横線が長いということは、データが似ていないことを意味します。
横線が長い箇所は、お互い似ていない回答者・クラスター同士が、クラスタリングされ始めたポイントだと解釈できます。その箇所でクラスタリングを終えれば、似ている回答者でクラスターを構成できるというわけです。
クラスタリングを終えるポイントがわかったら、その時点でのクラスターの個数を数えます。クラスターの個数を数える仕方としては、止めた範囲内における横線の本数を数えます。
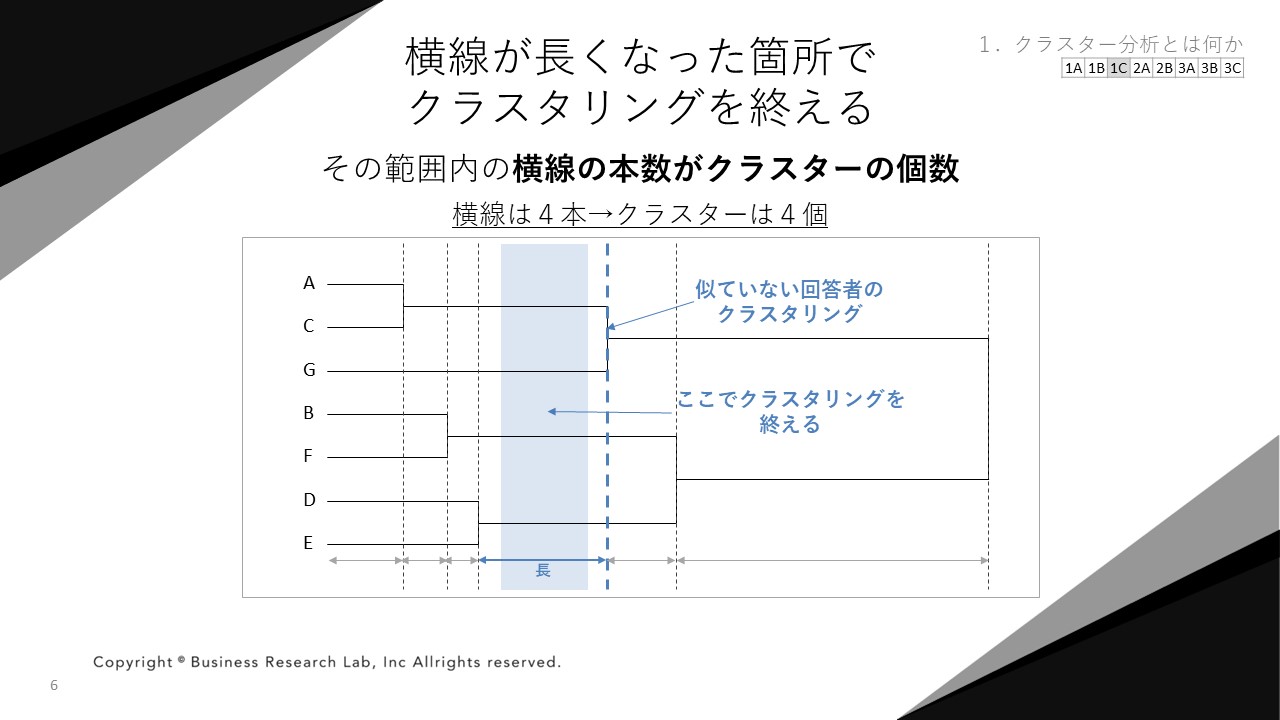
上図の青い範囲の中では、横線が4本あります。この時点では、クラスターが四つあったと判断できます。このデンドログラムから、回答者は四つのタイプ(クラスター)に分けて解釈するのが良さそうだと判断できるのです。
4クラスターに分けると決めたら、クラスターごとに各指標の平均を算出し、それぞれの特徴を把握していきます。
例えば、先のデンドログラムは、仕事への満足度、同僚への満足度というデータを取りクラスター分析を行った結果のものと仮定します。2つの満足度について各クラスターの平均を算出し、特徴を見ていきましょう(下図)。

図中の表で、赤い色に塗った部分は得点が高い傾向、青く塗った部分は得点が低い傾向、色塗ってない部分は得点が平均的であるとお考えください。
クラスター1(CL1)は両得点が高いクラスター、クラスター2(CL2)は両方の得点が低いクラスターと言えます。そして、クラスター3(CL3)は、同僚への満足度のみが低く、クラスター4(CL4)は、同僚への満足度のみが高いといった特徴があります。
ここから最後の過程、タイプ分けの議論に入ります。このような各クラスターの特徴を見て、分析者自身が各タイプの意味合いを解釈し、命名する必要があります。例えば、次のような命名が考えられます。
- CL1は満足度がどちらも高い→「全体的満足」タイプ
- CL2はどちらも低い→「全体的不満」タイプ
- CL3は同僚への満足だけ低い→「同僚不満」タイプ
- CL4は同僚への満足だけが高い→「同僚満足」タイプ
分析の進め方
クラスター分析を実際に行う際の展開について、より具体的に紹介します。五つの指標を用いてクラスター分析を実施するという、架空のデータで見ていきましょう。
指標の事前確認と分析の実施
クラスター分析前の下準備として、初めに、クラスター分析に用いる指標の間で、得点の取り得る範囲が揃っているかを確認します。揃っていない場合は、事前にデータの標準化を行います。標準化とは、ある指標の得点範囲を平均0, 標準偏差1にする計算処理のことです。
続いて、クラスター分析を実施します。実践的には、分析結果として出力されるデンドログラムの確認から始めることが多いでしょう。今回の200名の仮想データを解析してデンドログラムを出すと、次のようになったとします。
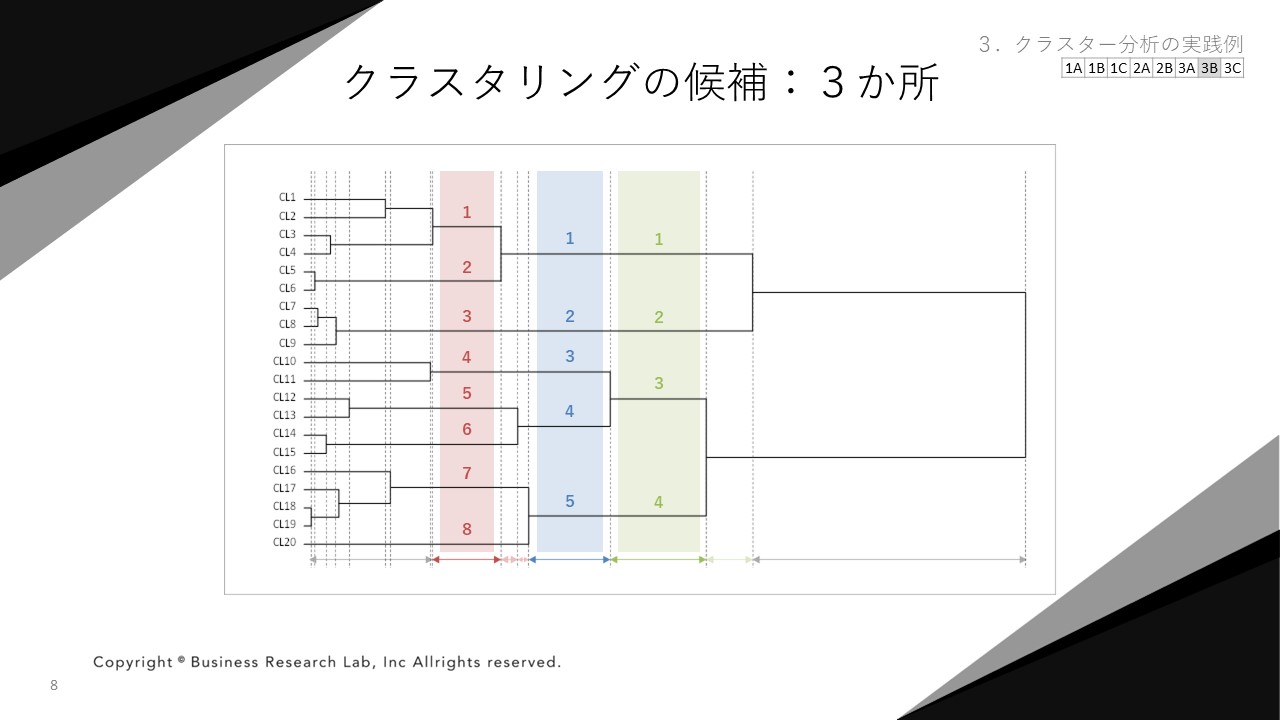
デンドログラムにおいて、横線が長くなった箇所を確認します。今回の結果では、横線が長くなる箇所が、赤、青、緑色に示した部分のように複数存在しています。それぞれの部分に関して横線の数を数えることで、クラスターの個数がわかります(赤:8クラスター、青:5クラスター、緑:4クラスター)。
このように、横線が長い箇所が複数あるパターンも多々あります。タイプ分けの複数の可能性が示されているので、全てのパターンでクラスターの特徴を確認します。その特徴を見比べることで、「最も有効なタイプ分けはこれだ」と分析者が解釈し、クラスター数を決定します。
クラスター数の模索:推奨数は4~6個
クラスター数を模索するにあたって、回答者のタイプ分けを目的とするなら、その数は4個から6個の間で捉えることを推奨したいと思います。

組織サーベイのデータを用いてクラスター分析を行うと、多くの場合で、ある二つのタイプが出てきます。全ての得点が高く、とても優秀なタイプ(上図の一番右側)と、全部の得点が低く、いわば苦労しているタイプ(上図の一番左側)です。
この2つのグループが特に出がちなのですが、クラスター分析でタイプ分けする際に着目すべきは、その間にいる中間層です。そこにどういった人がいるのかを見ていくのが重要です。クラスターの数を4~6個に設定すると、中間層として2~4タイプ分を確保できます。それによって、さまざまなタイプを確認しやすくなるのです。
もちろん、7個以上とタイプはさらに増やしてもよいのですが、その場合、中間層のタイプの違いを説明するのが難しくなってきます。「解釈が難しい」と感じたら、4個から6個のクラスターでやってみましょう。
クラスター数を変えてタイプを比較
今回の仮想データの結果では、8クラスターの可能性も示されましたが、このタイプ数はやや多いと思えます。5クラスターの可能性(青い部分)と、4クラスター(緑の部分)でタイプ分けを行い、それぞれの分け方によるタイプの特徴を比較してみます。
比較に際しては2つの点を考慮してください。まず、タイプ分けを有意義に解釈できるか。出てきたタイプはどのようなものか、実際に使えそうな有用なものかが大事です。次に、各クラスターの人数は十分か。以降の分析に応用するためにも、各タイプに20名以上は欲しいところです。
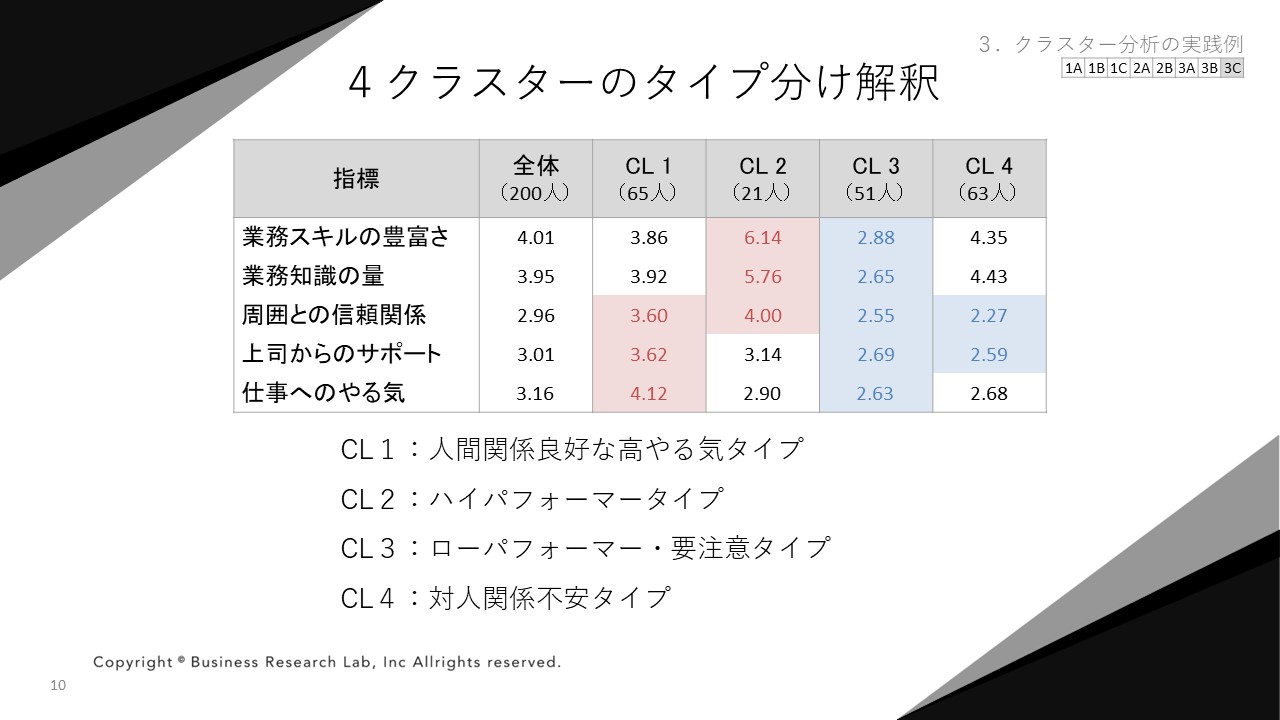
架空のデータで、4クラスターにタイプ分けした結果が上図です。赤い部分は高得点、青い部分は低得点の箇所です。各クラスターには以下のような特徴があります。
- CL1:「周囲との信頼関係」や「上司からのサポート」など対人関係に関する得点が高い→人間関係が良好なタイプ
- CL2:「業務スキルの豊富さ」や「業務知識の量」など業務に関する能力の得点が高い→ハイパフォーマータイプ
- CL3:全てが低い→ローパフォーマーで注意が必要なタイプ
- CL4:人間関係に関する指標だけやや得点が低く伸び悩んでいる→対人関係が不安なタイプ
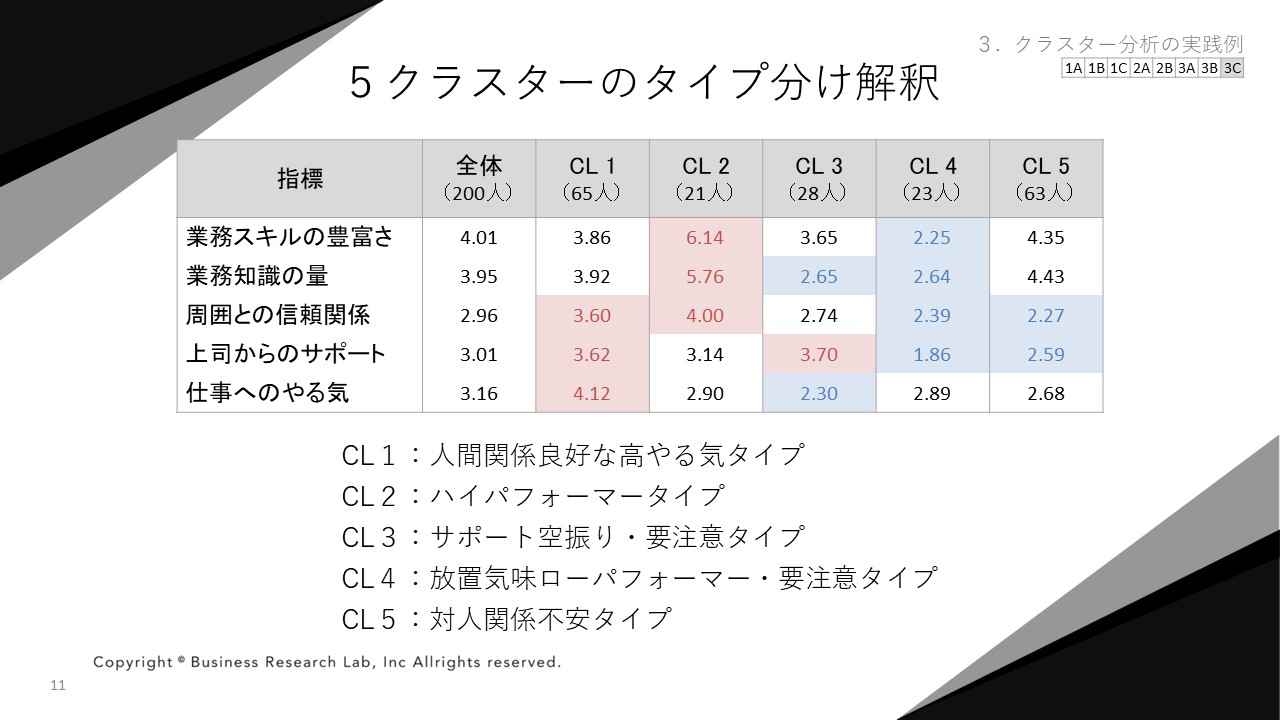
同じデータを5クラスターで分けた結果を、もう一つ出力して見てみます。CL1、CL2、CL5は、4クラスターで見られたタイプと同じような内容のため割愛します。特徴的なのはCL3とCL4です。4クラスターで分けた場合とでは、違いがあることがわかります。
まずCL3は、上司からのサポートの得点は高いものの、「業務知識の量」と「仕事のやる気」はやや損なわれています。ここから、上司が頑張ってサポートしても従業員が伸び悩んでいる、サポート空振り要注意タイプと解釈できます。
CL4は、やる気以外の指標全ての得点が低いうえに、人間関係に関する得点も低いため、社内で放置されてパフォーマンスも低いという、対人関係に問題や不安を抱えていそうな要注意タイプだと解釈できます。
以上の4タイプ・5タイプのタイプ分けを比較すると、共通点と相違点があることがわかります。どちらのタイプ分けを採用するのかは、データ分析を超えた現場目線の判断が迫られます。
今回の場合、4タイプと5タイプのタイプ分けの違いは、ローパフォーマータイプの細分化にありました。つまり、ローパフォーマーを細分化するかどうかが、タイプ分け判断の分かれ目となります。これは統計学的には判断できないため、現場の問題意識に応じて決める必要があります。
クラスター分析を実践する際、複数のタイプ分けの結果を比較し、最後は現場の問題意識とすり合わせるフェーズを多く含みます。そこがクラスター分析の難点でもあり、面白みでもあります。
クラスター分析を実施する際の注意点
クラスター分析の注意点を、二つ取り上げます。まず、類似した指標は含めないことです。よく似た指標ばかり入れたクラスター分析は、有効なタイプ分けが得にくくなります。
測定内容が類似した指標では、回答同士が強く関連します。そのため、タイプ分けでは、全部とても高いか低い、全部やや高いかやや低いなど、タイプ分けが程度問題になってしまうのです。
クラスター分析は、あまり似ていない質的に異なる指標を用いて分析するよう計画するのが良いでしょう。
もう一つは、得点の取り得る範囲が異なる指標を用いる場合です。クラスター分析には複数のデータを投入できますが、例えば、100点満点で測定する指標や、9段階評定の指標では、得点の幅が異なります。こうしたデータをそのままクラスター分析にかけると、距離の計算がおかしくなり、クラスタリングの意味もなくなります。
先ほどの実践例でもこの問題がありましたが、得点の範囲が異なる指標を用いてクラスター分析をする場合は、分析を実施する前に回答データを標準化する必要があります。クラスター分析を行う際は、分析に用いる指標の得点幅を確認するよう注意しましょう。
クラスター分析の実践的意義
一律の対策と個別対策の「中間」を実現
伊達:
私からは、クラスター分析の活用についてごく簡単に説明します。結論を先に言うと、クラスター分析によって「一律の対策」と「個別の対策」の間に当たることが検討できます。
一律の対策とは、全社員に同じ施策を講じていくような場合を指します。みんなに当てはまる制度を導入するというものです。一律の対策を打つと、その対策がうまくはまる社員もいれば、なかなかはまらない社員もいます。
他方で、個別の対策とは、各社員で対策を変えていくという考え方です。例えば近年、1on1が盛んに行われています。これは、それぞれの社員の状態を把握した上で、個別の対策を打つための方法の一つです。個々人の事情に応じて対策を打つのは、ある意味で理想的です。しかし、社員の数だけ事情はあります。対策の検討と実施に大きなコストがかかります。
このように、一律の対策も個別の対策も魅力と限界がありますが、クラスター分析を用いれば、両者の間に当たるようなアプローチが可能になります。タイプ分けに基づき、タイプ別の対策を打つというアプローチです。
タイプ分けを活かした施策の例
タイプ別の対策の例を挙げましょう。ワークライフバランスの推進のため、業務時間後のメール禁止という対策を講じたとします。この施策を「うれしい」と思う人もいれば、うれしくない人もいます。
仕事と家庭を分けたいタイプの人は、業務時間外のメールは、残業時間も含めて禁止となれば喜ばしいことでしょう。しかし、仕事と家庭を一緒くたに考えているタイプの人にとっては、あまり歓迎されません。
この例は、タイプによって適切な対策が異なる可能性があることを示唆しています。タイプをうまく分けることができれば、より有効な対策のターゲットを定められます。
もう一つの例として、若手社員の育成を挙げてみます。若手社員と一口に言っても、「沢山サポートを受けたい」と思う人もいれば、「自分に任せてください」と思う人もいるでしょう。若手社員をタイプ分けすれば、それぞれのタイプに応じた育成アプローチを考えていけます。
サイコグラフィック属性に基づくタイプ分け
もしかすると「うちの会社では、すでにタイプ別の対策を行っています」という人もいるかもしれません。しかし、タイプを分ける際の指標として、これまでは「デモグラフィック属性」が多かったのではないでしょうか。例えば、性別、年代、役職などで分けた対策です。
これに対して、組織サーベイを用いてクラスター分析を行えば、態度、性格、志向性、嗜好など、サイコグラフィック属性に基づいて、タイプ分けを行うことができます。これまでにない切り口でタイプ別の対策を検討できる点が、クラスター分析の意義だと思います。
Q&A
Q1:投入する変数はできるだけ増やすか、厳選すべきか
能渡:
これは、厳選したほうがいいですね。クラスター分析では、それぞれのタイプの特徴を判断するプロセスが入ります。指標をたくさん入れると、何十個もある特徴の違いをタイプごとに考える必要があり、タイプの解釈が困難・煩雑になります。
また、指標をたくさん入れると、タイプ分けに関連しない指標も出てきます。そうした指標があると、距離の計算がゆがみ、本来の分かれ方と異なるクラスターが形成されるリスクがあります。
Q2:4象限による解釈と比べてクラスター分析の良さはどこにあるか
能渡:
2軸で切って4象限に分ける方法は、多く使われるものです。分かりやすさがある反面、厳密な運用は簡単ではありません。二つの軸が完全に無相関で、データをプロットしたときに、きれいに4象限にデータが分かれてくる必要があるからです。
実際には、それらの条件を満たすデータは少ないと思います。つまり、2軸4象限はデータの実態に即していない場合があるのです。
それと比べたクラスター分析の良さとしては、クラスター数を4~5と増やす中で、中間層に着目できる点が挙げられます。「確かにこんな人はいるのを見落としていたな」と思えるタイプが見つかるはずです。
Q3:投入する指標に制約はあるか(自己評価と他者評価を同時に投入するなど)
能渡:
クラスター分析は、距離を計算するだけという単純な計算方式です。究極的には、いわゆる連続的な量的データであれば、どのようなデータでも分析ができてしまいます。だからこそ、分析後のタイプ分けを解釈することが重要になります。
Q4:分析の前に仮説を持っておくのが良いか、データに忠実になるのが良いか
伊達:
仮説を持っておいてもいいですし、そのことによって投入する指標の候補を考えることができますが、仮説に固執するのは問題ですね。
能渡:
クラスター分析は、データに基づいて分析するという性格が強い手法です。仮説どおりにデータが分かれるかは分かりません。仮説にこだわり過ぎて苦しむこともあるかもしれません。柔軟に仮説を修正しながら分析をしていただければと思います。
Q5:クラスター分析ができる統計ソフトや参考文献は何があるか
能渡:
クラスター分析は、簡単な手法なので、どの統計ツールにも入っているはずです。
伊達:
参考文献としては、能渡さんが書いたクラスター分析に関するコラムが挙げられます。今回は十分に触れられなかった数理的な側面についても理解が深まる内容です。
[1] クラスター分析の数理的なメカニズムなど、より詳しい内容については当社のコラム「クラスター分析とは何か」を参照ください。



