

2026年3月17日
課題の解像度を高める手法を学ぶ:一般化線形モデルで広がる人事データ分析(セミナーレポート)

ビジネスリサーチラボは、2026年1月にセミナー「課題の解像度を高める手法を学ぶ:一般化線形モデルで広がる人事データ分析」を開催しました。
近年、人事部門やマネジメントの現場では、データに基づいた意思決定の重要性が増しています。例えば、「離職が増えており、対策を検討するため何が原因なのかをデータ分析で導き出したい」と考える方は多いかもしれません。しかし、データ分析によって離職の要因を検討しようとしても、実は基本的な分析手法では適切に分析することはできません。
離職だけではありません。他にも、「何が研修参加を後押ししているのか」「出社・ハイブリッド・完全リモートといった働き方の選択に影響するのは何か」といった問いに答えようとしても、一般的なデータ分析の枠組みでは十分な精度で検証することが難しいのです。
こうした課題を解決する統計手法が「一般化線形モデル」です。一般化線形モデルを使えば、様々な人事データにおいて「離職を促進している自社の要因はなにか」を分析するなど、基本的な手法では扱えない様々な分析が可能となります。
データ分析の経験が浅い方でも、専門知識を実務に結びつけられる内容です。人事・経営の現場で役立つ分析アイデアをわかりやすく解説し、その実践例を紹介しました。
※本レポートはセミナーの内容を基に編集・再構成したものです。
回帰分析の強みと落とし穴
能渡:
データ分析の重要性が高まる昨今、実務の現場では「要因の検証」と「スコアの予測」という二つのアプローチが頻繁に行われています。前者は「ある成果指標を高める重要な要因は何か」を探るものであり、後者は「現状の指標から将来の成果指標がどの程度になるか」を予測するものです。これらの関心に応える代表的な統計手法が「回帰分析」です[1]。
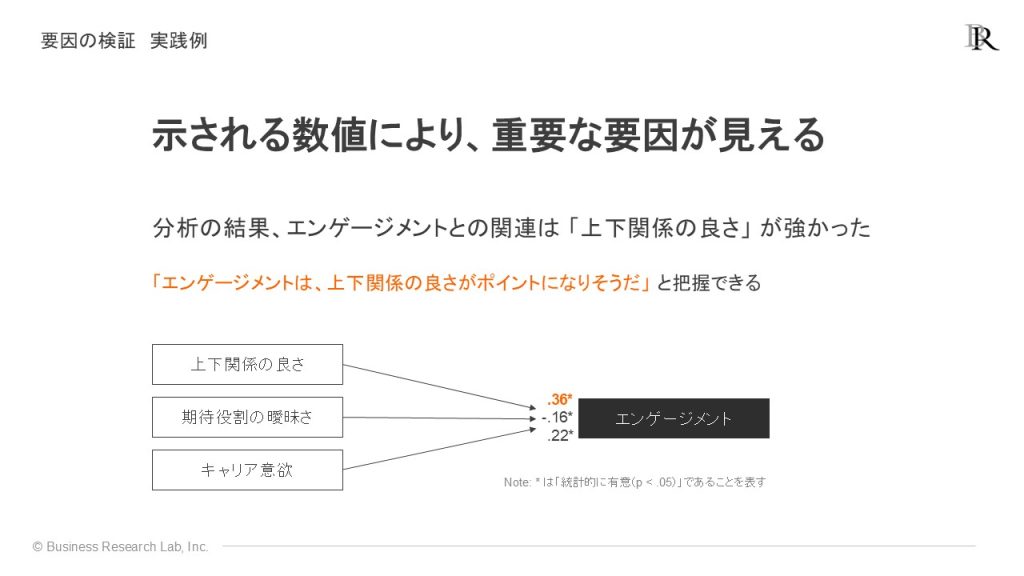
回帰分析を用いると、成果指標に対して種々の影響指標がどの程度関連しているかをデータから示すことができます。例えば、「エンゲージメントは何によって高まるのか」という問いに対し、上司部下(上下)関係の良さ、役割の曖昧さ、キャリア意欲といった複数の要因をデータで検証し、どの要因が最も強く関連しているかを特定することが可能です。
また、一度回帰分析を実施すると、成果指標の状態を予測できる数式が得られます。具体例として、適性検査の結果からあるタスクのパフォーマンスを予測するケースが挙げられます。過去のデータに基づいて「パフォーマンス = 切片 + 係数 × 性格特性」といった数式を得ることができ、新たに入社した社員の適性検査結果をこの式に当てはめることでパフォーマンスの高さを推測し、そのタスクが社員にマッチしていそうかを見積もることができるのです。
非常に強力な手法である回帰分析ですが、実は無視できない「制約」が存在します。回帰分析のロジックでは、成果指標のスコアを「影響指標で予測できる部分」と「予測できていない部分(残差)」に分けて考えますが、この「残差が正規分布している」ことが、正確に回帰分析を実行するための条件となっています。

もし残差が正規分布していないデータに対して通常の回帰分析を用いてしまうと、算出された係数や予測値に誤りが生じる落とし穴にはまってしまいます。人事データには、この制約に抵触して通常の回帰分析ではうまく扱えない種類のデータが数多く存在しているのが現実です。
多様なデータを分析できる「一般化線形モデル」
では、残差が正規分布しないような成果指標を分析したい場合、私たちはどうすればよいのでしょうか。この限界を乗り越え、回帰分析の枠組みをより広く拡張した手法が「一般化線形モデル(GLM: Generalized Linear Model)」です。

まず、通常の回帰分析が苦手とするデータの具体例を確認しておきましょう。代表的なものに、離職の有無や研修への参加・不参加といった「二値データ」があります。これらは0か1かの二つの値しか取らないため、通常の回帰分析では残差がきれいな正規分布を描くことはありません。他にも、資格保有数や欠勤日数などの「カウントデータ」、ランク評価のような「順序データ」、あるいは「割合データ」といったものは、残差が正規分布しづらいデータの代表例です。
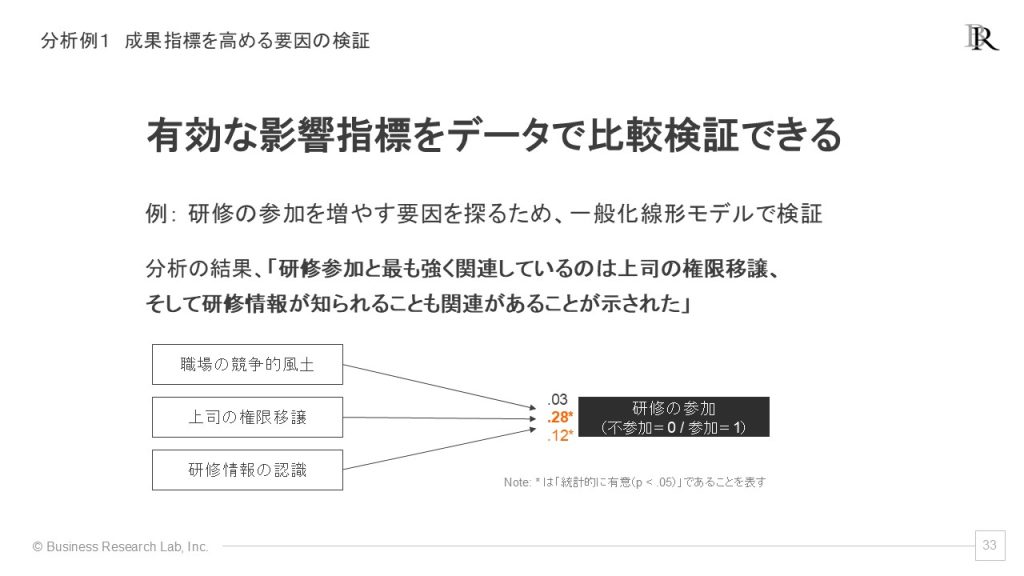
一般化線形モデルを用いれば、こうした特殊な性質を持つ成果指標であっても、回帰分析と同等の精度で要因検証や予測を行うことができます。例えば「研修の参加を増やす要因」を分析したい場合、成果指標は「参加・不参加」の二値データになります。一般化線形モデルで分析した結果、「上司の権限移譲」が最も強く研修参加に関連しているといった知見が得られれば、マネジメントへの働きかけという具体的な対策を打つ根拠になります。
加えて、成果指標の予測の面でも回帰分析と同じように予測式を得ることが出来ます。例えば、業務経験のデータからその社員が将来的に「スペシャリスト」や「ジェネラリスト」になる確率を算出する、といった高度な活用が可能です。このように、人事データのリアリティに即した形で分析を行えるのが、一般化線形モデルの最大の魅力です。
一般化線形モデルがどのように回帰分析を拡張しているのか、その専門的な仕組みを少しだけ触れます。ポイントは「分布の設定」と「リンク関数」という二つの設定にあります。通常の回帰分析は「残差が正規分布すること」を前提にしていましたが、一般化線形モデルではその前提から離れて、データの種類に応じて「二項分布」や「ポアソン分布」といった最適な分布を成果指標に直接仮定します。
さらに「リンク関数」という数学的な変換を用いることで、そのままでは数式に当てはめにくい特殊な数値を調整し、適切な予測値を導き出せるようにしています。これらの設定はデータの性質によってある程度自動的に決まるため、リンク関数をひとつひとつ暗記する必要はありませんが、こうした拡張によって分析の幅が広がっているという点をご理解いただければと思います。

一般化線形モデルを活用する際の注意点
一般化線形モデルは非常に優れた手法ですが、正しく使いこなすためにはいくつかの注意点も押さえておく必要があります。
一つ目は「多重共線性」の問題です。これは通常の回帰分析にも共通する注意点ですが、影響指標の中に互いに非常に強く相関している指標が混ざっていると、分析結果が不安定になり、どちらが真の要因なのか判断できなくなってしまいます。似すぎている指標は、分析の際にどちらか一方に絞るなどの事前処理が必要です。
二つ目は、特に「二値データを扱う際のサンプルサイズ」の問題です。二値データを成果指標とする一般化線形モデルの分析結果を安定させるためには、EPV(Events Per Variable)が重要になります。具体的には、「二値データのうち少ない方の人数が、分析に投入する影響指標の個数の10倍以上存在することが望ましい」とされています。
例えば、「参加/不参加」という二値データが入っている研修参加の有無を成果指標として、5つの要因を影響指標に投入して一般化線形モデルの分析をしたいなら、「参加または不参加のうち少ない方のグループに、要因の個数5個の10倍、つまり50人以上のデータが必要」という目安です。
これらの注意点に留意しつつ、適切にモデルを選択した一般化線形モデルの分析を行うことで、人事課題の解像度はより一層高まっていくでしょう。
人事データの特徴と分析の壁
伊達:
人事やマネジメントの現場において、経験や勘だけに頼るのではなく、蓄積されたデータに基づいて意思決定を行いたいという機運が高まっています。しかし、いざ手元にある人事データを分析しようと試みたとき、多くの担当者が一つの壁に直面します。それは、教科書的な統計手法が、人事データの現実に必ずしも適合しないという問題です。
一般に広く知られ、多くの表計算ソフトでも実行できる手法に「線形回帰分析」があります。これは、ある変数の値を、他の複数の変数の値を用いて予測したり、関連の度合いを検証したりするための手法です。しかし、線形回帰分析を適切に適用するには、いくつかの条件を満たす必要があります。特に重要なのが、データが連続的な数値をとり、予測との誤差が正規分布に近い形をとるという点です。例えば、身長や体重、あるいは製品の売上金額といったデータであれば、この手法と相性が良く、解釈しやすい結果を得ることができます。
ところが、人事の実務で関心の対象となる事象の中には、このような性質を持たないものがあります。例えば、「離職するか、しないか」「昇格するか、しないか」といった事象は、0か1かという二つの値しかとりえません。研修の受講回数や欠勤日数などは、0以上の整数をとる「回数」のデータであり、マイナスの値をとることはありません。S・A・B・C・Dといった人事評価は順序を表していますが、それぞれのランク間の差が均等であるとは限りません。
このように、人事データの多くは、離散的であったり、とりうる値に制限があったりと、単純な正規分布の枠組みでは捉えきれない構造をしています。こうしたデータの特性を考慮せず、漫然と通常の線形回帰分析を適用することはリスクを伴います。確率がマイナスになるといった理論的にあり得ない予測値が算出されたり、要因の影響力を誤って推定してしまったりします。データに基づく意思決定を行うためには、データの形式に合わせて適切な分析手法を選択する必要があります。
そこで本日のテーマとなっている「一般化線形モデル(Generalized Linear Model: GLM)」という分析の枠組みが役に立ちます。一般化線形モデルは、通常の線形回帰モデルを拡張したものです。データが従う確率分布を正規分布に限定せず、二項分布やポアソン分布など、データの生成メカニズムに合わせて柔軟に設定することができます。これによって、人事データ特有のリアリティを損なうことなく、数理的に妥当な分析を行うことが可能になります。
一般化線形モデルが活躍する三つの場面
人事データ分析において、一般化線形モデルの適用が推奨される場面は、大きく分けて三つ存在します。
第一の場面は、成果指標が「二値変数」であるケースです。これは、離職の有無、昇格の有無、異動希望の有無など、結果が「イエス」か「ノー」のいずれかになるデータを指します。これらは統計学的にはベルヌーイ分布や二項分布に従うデータとして扱われます。もし、このような0か1かのデータに対して通常の線形回帰分析を行うと、計算上の予測値が0を下回ったり1を超えたりすることがあります。確率は定義上0から1の間に収まる必要があるため、これでは解釈ができません。
一般化線形モデルの一種であるロジスティック回帰分析を用いれば、成果指標が1となる確率(生起確率)を、0から1の範囲に収まるように変換して推定することができます。これによって、ある従業員が離職する確率や、昇格する確率を、数学的に矛盾なく算出することが可能になります。
第二の場面は、成果指標が「計数データ(カウントデータ)」であるケースです。ある期間内の欠勤日数、研修への参加回数、社内公募への応募回数など、負の値をとらない整数がこれに該当します。計数データは、多くの場合、0回付近にデータの頻度が集中し、回数が増えるにつれて頻度が減少するという、右に裾を引いた分布形状をとります。また、平均的な回数が多い属性ほど、データのばらつきも大きくなる傾向があります。
こうした特徴を持つデータに対しては、ポアソン回帰分析や、データのばらつきが特に大きい場合に適した負の二項回帰分析など、カウントデータ専用のモデルが有効です。これらを用いることで、マイナスの値をとらないという制約や、データのばらつき方を数理的に考慮した上で、何が回数の増減に関連しているのかをより適切に分析することができます。
第三の場面は、成果指標が「順序変数」であるケースです。典型的な例は、S・A・B・C・Dといった段階的な人事評価です。これらは順序関係を持っていますが、数値としての等間隔性は保証されていません。S評価とA評価の間の実力差が、C評価とD評価の間の差と等しいとは限りません。順序変数を便宜的に5点、4点、3点といった数値に置き換えて線形回帰分析を行うことは、暗黙のうちに尺度の等間隔性を仮定することになり、分析結果にバイアスを生じさせる可能性があります。
順序ロジットモデルなどの一般化線形モデルを用いることで、順序情報のみを保持したまま、各段階に分類される確率を統計的により妥当な仮定のもとでモデル化し、要因の影響を検討することができます。
分析から得られる二つの実務的便益
一般化線形モデルを適切に用いることで、人事領域においては実務上、大きく二つの便益を得ることができます。
一つ目の便益は、他の要因の影響を統計的に考慮した上での、精緻な「要因ごとの影響度推定」です。単純な集計や相関分析だけでは、見かけ上の関係性と真の関係性を区別することが困難な場合があります。例えば、残業時間が長い従業員ほど人事評価が低いというデータが観測されたとします。しかし、これは残業自体が評価を下げているのではなく、実は「上司との1on1ミーティングの頻度が低い」という別の要因が、残業の増加と評価の低下の両方を引き起こしているのかもしれません。
一般化線形モデルを用いることで、上司とのコミュニケーション頻度など手元にある他の変数の影響を一定に保った状態で、残業時間が評価に与える影響力を推定することが可能になります。無論、データとして観測できていない本人の資質や、部署ごとの独特なカルチャーなどの影響が完全に消えるわけではありません。しかし、単純な集計だけで判断するよりも、表面的な相関関係に惑わされることなく、背景にある要因の重みをより妥当な形で捉え、効果的な施策立案につなげることができます。
二つ目の便益は、個々の従業員や候補者に対する精緻な「確率予測」が可能になる点です。組織全体の平均的な傾向を把握するだけでなく、特定の属性や背景を持つ個人が、ある事象を起こす確率をモデルから算出することができます。この便益は、例えば管理職登用の場面で価値を発揮するでしょう。
管理職への適応確率(活躍確率)の予測を考えてみましょう。過去に管理職に昇格した従業員のデータを分析し、プレイヤー時代の評価、適性検査の結果、360度評価のスコアなどが、昇格後のパフォーマンス(高評価を得られるかどうか)にどのように影響しているかを一般化線形モデルでモデル化します。このモデルを新たな昇格候補者に当てはめることで、「過去の傾向に基づくと、Aさんの適応確率は90%と推計される」といった定量的な予測が可能になります。
ここで注意すべきは、この数値はあくまで「過去の評価基準がそのまま続くと仮定した場合の予測値」であり、絶対的な予言ではないという点です。また、算出される確率には必ず統計的な「幅(誤差)」が含まれます。構築したモデルの精度検証はもちろん、過去のデータに含まれるバイアスを再生産していないかを検証した上で用いる必要がありますが、人間の判断を補う重要な補助線として機能します。
ここにおいて重要なのは、この予測を選別の道具として使うのではなく、育成や支援のための意思決定に活用することです。例えば、適応確率が高いAさんについては通常通りの登用プロセスを進める一方で、適応確率が低いと予測されたBさんについては、昇格直後から半年間メンターを配置したり、管理職研修を手厚く実施したりといった予防的な介入を行う判断ができます。データに基づいて個別のリスクを事前に察知し、限られた人的・時間的リソースをどこに重点的に配分すべきかを合理的に決定できます。
一般化線形モデルがもたらす可能性
人事データ分析の目的は、単にデータを集計して可視化することだけではありません。データの背後にあるメカニズムを理解し、より良い未来を予測し、効果的なアクションにつなげることにあります。
一般化線形モデルは、人事の現場に存在する「正規分布に従わないデータ」を、無理に加工することなく扱うための理論的基盤を提供します。データの性質に合致した適切な統計モデルを選択することは、人事データ活用の精度を高めるための重要な一歩です。もちろん、データには、極端に発生頻度が少ない事象や、現場の複雑な人間関係など、モデルだけでは捉えきれない限界も存在します。統計モデルは万能ではありません。
しかし、一般化線形モデルという「データの歪みを歪みとして扱えるレンズ」を持つことで、経験と勘だけに頼るよりも、解像度の高い議論が可能になります。モデルの限界を理解した上で使いこなすことが、組織と個人の可能性を最大化させる鍵となるはずです。
Q&A
Q:分析結果が、経営者の「勘」と一致した場合は喜ばれますが、経営者が推進したい施策の効果を否定するような結果が出た場合、データの正当性をどう主張すれば良いでしょうか。政治的な圧力に負けず、データドリブンな人事を進めるための心得があれば教えてください。
能渡:
これはデータ分析の現場では本当によくある話です。分析を厳密に行えば行うほど、当初の分析結果のイメージや経営者の直感とは異なる結果が出ることは珍しくありません。
そのような場合の説明のコツとして、「誰にでも分かりやすい、ベーシックな分析結果もあわせて用意しておく」というアプローチを提案します。今回ご紹介した「一般化線形モデル」のような応用的な手法は、本質を突く反面、直感とは乖離した結果になることも多いです。そこで、説得の際には二段構えの構成をとるのが良いでしょう。
第一段階として、まずは一般的な統計手法による分析結果をお見せします。具体的には、例えば成果指標の二値データについて、二つのグループの平均値を比較する「t検定」や、データ同士の関連性を見る「相関分析」といった基礎的な手法を用いて結果を示します。これらは変数を絞って単純化して結果を見られるため、経営者の直感に近い結果が出やすい傾向があります。初めにこの結果を提示し、「基本的な手法で見ると、予測された通りこのような傾向が出ています」と伝え、まずは安心感を得ます。
その上で、第二段階として本題に入ります。「しかし、より詳細に要因を分解し、発展的な分析手法を用いて深掘りすると、実は表面的な傾向とは異なる真実が見えてきました」と説明するのです。
発展的な分析結果により最初から直感を否定するのではなく、「予測通りの部分もあるが、深く見ると意外な事実があった」というストーリーで説明すれば、相手も頭ごなしに否定されたとは感じず、分析結果を受け入れやすくなります。予測通りの結果が示されやすい基礎的な分析と、意外な真実を出す発展的な分析。この二面的なアプローチが、政治的な壁を乗り越える有効な手段といえます。
伊達:
経営者にとって、信じて進めてきた施策の効果が「ない」という結果は、まさに「不都合な真実」であり、心理的な抵抗感が生まれるのは当然です。
ここで大切なのは、この状況を「正しいデータ」対「間違った経営者の勘」という対立構造に持ち込まないことです。分析者の中には「データは正義」と考え、相手を過剰に説得しようとする人もいます。それでは相手も意固地になり、建設的な議論ができません。データは「論破の道具」ではなく、あくまで「対話の質を向上させるためのツール」として捉えるべきでしょう。
もし結果が食い違ったら、「なぜ、社長は効果があると感じていたのでしょうか?」と問いかけ、一緒に背景を解釈してください。対話を深めると、さらなる分析のヒントが得られることがあります。
例えば、データ上は「全体では効果なし」でも、経営者が効果を感じていた理由を探ると、「特定の部署や年代には確かに効果があった」というケースが見つかるかもしれません。全体では見えない「条件付きの真実」は、現場感覚を持つ経営者との対話から生まれます。
脚注
[1] 回帰分析については、以下の当社コラムでくわしく解説しています。
登壇者
 伊達 洋駆 株式会社ビジネスリサーチラボ 代表取締役
伊達 洋駆 株式会社ビジネスリサーチラボ 代表取締役
神戸大学大学院経営学研究科 博士前期課程修了。修士(経営学)。2009年にLLPビジネスリサーチラボ、2011年に株式会社ビジネスリサーチラボを創業。以降、組織・人事領域を中心に、民間企業を対象にした調査・コンサルティング事業を展開。研究知と実践知の両方を活用した「アカデミックリサーチ」をコンセプトに、組織サーベイや人事データ分析のサービスを提供している。著書に『60分でわかる!心理的安全性 超入門』(技術評論社)や『現場でよくある課題への処方箋 人と組織の行動科学』(すばる舎)、『越境学習入門 組織を強くする「冒険人材」の育て方』(共著;日本能率協会マネジメントセンター)などがある。2022年に「日本の人事部 HRアワード2022」書籍部門 最優秀賞を受賞。東京大学大学院情報学環 特任研究員を兼務。
 能渡 真澄 株式会社ビジネスリサーチラボ チーフフェロー
能渡 真澄 株式会社ビジネスリサーチラボ チーフフェロー
信州大学人文学部卒業、信州大学大学院人文科学研究科修士課程修了。修士(文学)。価値観の多様化が進む現代における個人のアイデンティティや自己意識の在り方を、他者との相互作用や対人関係の変容から明らかにする理論研究や実証研究を行っている。高いデータ解析技術を有しており、通常では捉えることが困難な、様々なデータの背後にある特徴や関係性を分析・可視化し、その実態を把握する支援を行っている。




{kind=link}
{kind=link}