

2025年8月15日
人事データ構造の原則:分析効率を高めるアプローチ

人事部門においては、採用、評価、育成、退職など多岐にわたるデータを扱い、近年は、それらを分析して意思決定に活かすことが求められています。しかし、せっかく貴重なデータを収集していても、それが分析しやすい形で整理されていなければ、その価値を十分に引き出すことはできません。
人事データの分析では、「どの従業員がどのような特性を持ち、どのようなパフォーマンスを示しているか」「どのような属性や経験を持つ従業員が長く定着するか」「どのような研修が従業員のスキル向上に効果的か」など、様々な問いに答えることが期待されます。これらの分析を効率的かつ正確に行うためには、データ構造が適切に設計されていることが前提となります。
適切なデータ構造とは、「きれいに見える」ということではなく、「統計的な分析手法やツールに適合している」ということです。例えば、エクセルでは見やすく整理されているように見えても、統計ソフトウェアで分析しようとすると様々な前処理が必要になるケースがあります。
本コラムでは、人事データを例に取りながら、統計分析に適したデータ構造とはどのようなものか、また、そのようなデータ構造を実現するためには何に注意すべきかについて解説します。
良質なデータ構造とは
統計分析では、データを「どういう形にまとめるか」が、分析手法の適用やソフトウェアの利用、または可視化のしやすさに影響します。ここでは、データ分析の現場で広く推奨されている構造を紹介します[1]。
基本的かつ重要なデータ構造の原則は「行が観測単位、列が変数」というものです。この原則は、どのようなデータ分析においても基礎となります。具体的には、行は1つの対象(例えば、1人の従業員)に対応し、列はその対象が持つ属性や指標を表します。例えば、人事データであれば、各行が1人の従業員を表し、列には従業員ID、氏名、年齢、性別、部署、役職、入社日、給与、評価点などが並びます。
この形を守ることで、「どのレコードがどの対象を示すのか」と「どの列がどの属性を示すのか」を、データを扱う人やプログラムの両方が理解しやすくなります。特にデータ解析ソフトウェアは、この形式(データフレーム)を標準としており、集計やモデルへの入力がスムーズに行えます。
統計分析の世界では、「Tidy Data(整然データ)」という概念があります。これは、ハドリー・ウィッカムが提唱した概念で、3つの原則を満たすデータを指します。一つ目は「各変数が1つの列をなす」こと、二つ目は「各観測単位が1つの行をなす」こと、三つ目は「各型(表全体)が1つの表(データセット)をなす」ことです[2]。これらを徹底することで、可視化や分析のコードが簡潔になり、作業者もデータ内容を誤認しにくくなります。
例えば、人事データにおいて、ある従業員の「部署」と「役職」を一つの列に「営業部・主任」のように結合してしまうと、部署別や役職別の分析が困難になります。「部署」と「役職」はそれぞれ独立した変数として別の列に格納しましょう。
ここで、データの形式について重要な概念があります。それは「ロング形式(Long Format)」と「ワイド形式(Wide Format)」の違いです。
ワイド形式は、各行がある対象(例えば従業員)を表し、その対象に関する複数の観測指標(例えば各年度ごとの評価スコアなど)を横方向(列)に並べる方法です[3]。例えば、従業員IDを行に、「2020年評価」「2021年評価」「2022年評価」などを列にした表がこれにあたります。この形式はExcelで直接見るときは分かりやすいですが、年度や指標が増えると列がどんどん増え、管理が煩雑になります。
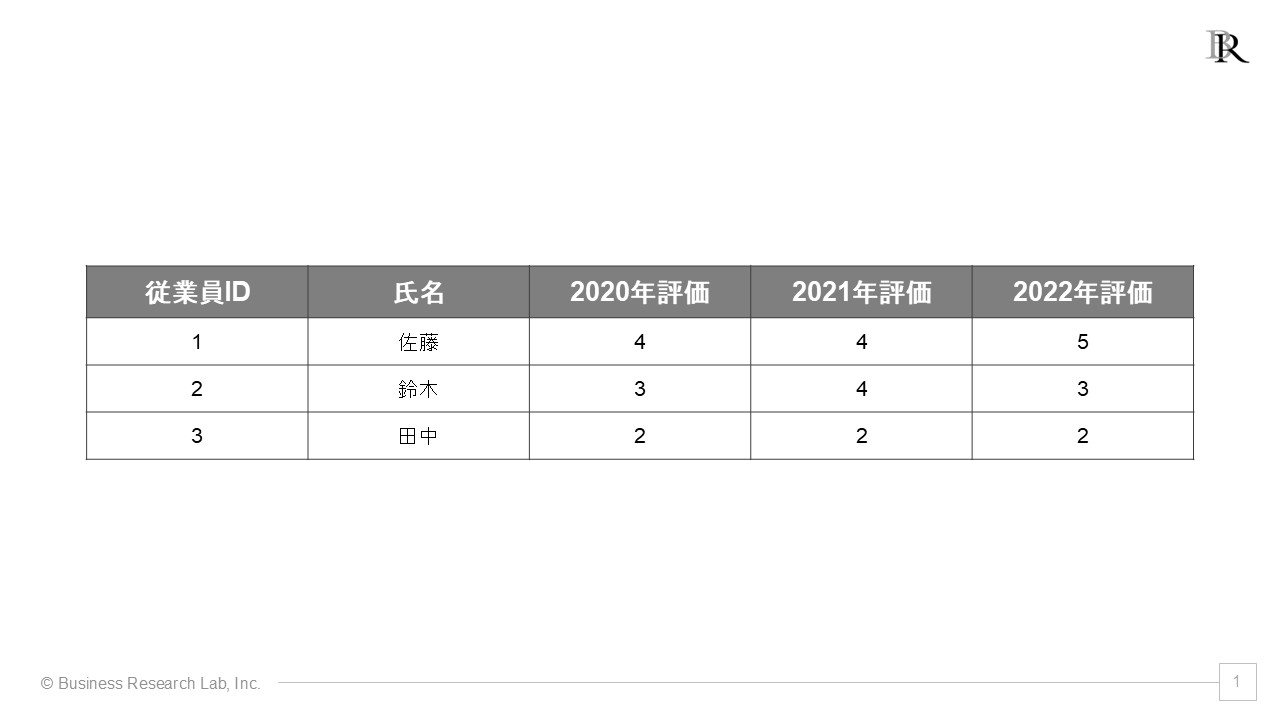
一方、ロング形式は、対象と時間(またはカテゴリー)と値のように、複数に分割して表にする方法です。先ほどの例でいえば、「従業員ID」「評価年度」「評価スコア」として、年次が異なる評価は新たに行を増やしていく形にします。ある従業員の3年分の評価データは3行に分かれて記録されます。
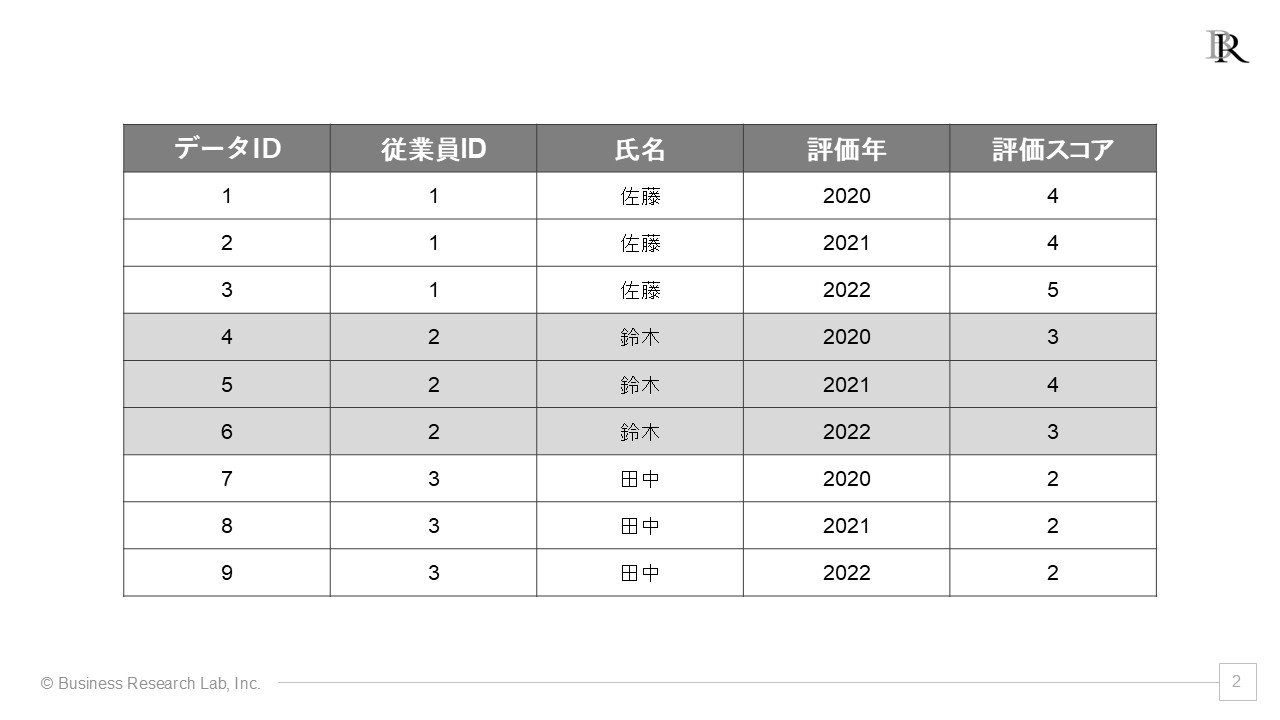
これら二つの形式は、どちらが良いのでしょうか。分析時は、多くの統計分析ソフトウェアやライブラリがロング形式のデータを前提に設計されているため、ロング形式が推奨されるケースが多いです。一方で、集計レポートやExcelでの配布用にはワイド形式が扱いやすく分かりやすい場合もあります。結局は、用途によって使い分けることになります。
幸いなことに、データ変換(ロングとワイドの相互変換)は比較的容易に行えます。例えば、ワイド形式の人事評価データがあるとします。このデータには「従業員ID」「氏名」「部署」「2020年評価」「2021年評価」「2022年評価」の列があります。これをロング形式に変換すると、「従業員ID」「氏名」「部署」「評価年度」「評価スコア」の列になり、各従業員について年度ごとに行が分かれます。この形式だと、「年度ごとの評価の平均値はどう変化しているか」「部署別に評価の分布はどう異なるか」といった分析が容易になります。
ただし、注意点もあります。ロング形式にする際、「従業員ID」「氏名」「部署」のような、時間によって変化しない(または変化が少ない)情報が各行に繰り返し現れることになります。これによって、データサイズが大きくなったり、一部の情報が更新された場合に整合性を保つのが難しくなったりする可能性があります。
分析しやすい形にするために
ここでは「行=観測単位、列=変数」の原則や、ロング形式・ワイド形式の使い分けを前提に、さらに実務で陥る可能性のある注意点や手間を要する部分について説明します。特に「主キーと繰り返し要素の分離」と「欠損値やデータ型の扱い」を取り上げます。
主キーと繰り返し要素の分離について考えてみましょう。統計分析をするうえで、各行が一意に特定される(同じ観測単位が複数回登場しない)ようにするのは大切です。この「一意に特定するための列または列の組み合わせ」を主キー(Primary Key)と呼びます[4]。
例えば、人事データがロング形式なら「従業員ID」、アンケート調査なら「回答者ID」、あるいは製品売上データなら「商品ID」と「日付」の組み合わせなどが主キーになり得ます。主キーがしっかり設定されていないと、行ごとの区別ができなくなり、同じ人が重複して集計される、あるいは上書きされて消えてしまうなど、データ処理上の問題が発生します。こうした問題は重複カウントエラーなどにつながり、分析結果に深刻な歪みをもたらします。
例えば、従業員の勤怠データを分析する場合、「従業員ID」だけでは主キーとして不十分です。なぜなら、一人の従業員は複数日にわたって勤務するからです。この場合、「従業員ID」と「勤務日」の組み合わせが主キーとなります。これにより、「ある日の特定の従業員の勤怠状況」を一意に特定できます。
次に、繰り返し要素について考えてみましょう。繰り返し要素とは、1つの主キーに対して複数回の記録が発生するようなデータのことです。例えば、1人の従業員に対して「勤務日ごとの勤怠」や「年度ごとの評価」などがこれにあたります。
これらは1つのテーブルに詰め込んでしまうと、同じ従業員が何度も行として現れ、さらに多くの列が「空欄」になったり「重複」したりしがちです。例えば、評価がない年の列がすべてNULLになる、同じ従業員名や部署名が何行にもわたって重複するといった状況が発生します。
そこで、繰り返し要素を別テーブル(たとえば「評価テーブル」「勤怠テーブル」など)として切り出し、従業員ID(主キー)で連結する方式が望ましいでしょう。こうすることで、更新時の整合性(ある従業員の所属部署を変更する際に、すべての行を更新しなくてはならないといったリスクを減らせる)や、テーブル同士を必要に応じて結合して分析することができます。
具体例を考えてみましょう。ある会社の人事データがあるとします。従業員の基本情報(ID、氏名、性別、生年月日、入社日など)は一つのテーブルにまとめ、評価データ(ID、評価年度、評価スコア、評価者コメントなど)は別のテーブルにまとめます。こうすることで、評価データが増えても基本情報テーブルは肥大化せず、また、基本情報が更新されても評価データに影響を与えません。分析時には、両テーブルを従業員IDで結合することで、必要な情報を組み合わせて利用できます。
主キー設定には注意点もあります。自然キーを使うか、人工キーを使うかという選択があります。自然キーとは、社員番号や製品の固有コードなど、実際に運用上で割り当てられるキーのことです。一方、人工キーとは、連番(1, 2, 3, …)など、データベース上で自動生成するキーのことです。
自然キーでも問題ない場合が多いですが、更新のリスク(社員番号が途中で変わるなど)があるときは注意が必要です。例えば、合併や組織再編により従業員IDが変更される可能性がある場合、古いデータと新しいデータの連続性が失われます。そのような場合は、システム内部では人工キーを使い、自然キーは別の列として保持するという方法も検討できます。
主キーが実質的に機能していないケースもあります。例えば、Excelで重複を許してしまっている、データ入力時に間違ったIDが入っている、などの問題です。そうした不正確なキーは重複カウントや欠損が多発してしまい、クリーニング作業に多大な手間がかかります。
複合キーの扱いも重要です。1つの列だけで主キーにならないとき、「従業員ID×年度」や「従業員ID×日付」などの複数列の組み合わせで主キーを構成します。これによって一意に観測を区別できれば、分析で日次や月次の指標を扱う際にも整合性が取りやすくなります。
続いて、欠損値やデータ型の扱いについて考えてみましょう。データ分析の初期段階において、「欠損値の処理」と「データ型の確認」は優先事項の一つです。
欠損値についてですが、それが発生する原因はさまざまです。入力ミスや入力漏れ、該当しない値が本来ある場合、機密情報で開示されない場合などが考えられます。入力ミスや入力漏れの例としては、担当者の入力忘れやシステム障害による未記録などがあります。該当しない値が本来ある例としては、退職日を聞こうとしても、まだ在職中の従業員には退職日が存在しない場合などがあります。機密情報で開示されない例としては、あるデータだけ社外秘で出せず、欠損として処理されるケースなどがあります。
欠損値は分析結果に影響を与えるので、「どの程度の欠損があるのか」「欠損が系統的に発生していないか」などをチェックし、適切な補正方法を検討することが重要です。例えば、単純に欠損値を除外して分析すると、特定の属性を持つデータが系統的に除外され、偏った結果になる可能性があります。欠損値の扱い方は様々な方法がありますが、どの方法が適切かは状況によって異なります。
次に、データ型の確認と整合性についてですが、データ型には、数値型(給与や年齢などの連続的・離散的な数値データ)、カテゴリカル型(部署や学歴など、いくつかのカテゴリーに分類できるもの)、文字列型(名前やIDなど、単純に文字情報として扱うもの)、日付・時刻型(入社日、勤怠の打刻時刻など)などがあります。
データ型が混在する例としては、Excelなどで入力されたデータを取り込むと、数値のはずが文字列になっている(0.2といった数値を0,2と入力している、「0」を「O」と誤入力しているなど)ケースがあります。本来はカテゴリ(離散的な属性)で扱うべきものを数値列にしてしまい、平均をとるといった誤集計をしてしまうこともあります。日付が「YYYY/MM/DD」の文字列として入力されており、正しく時系列解析や期間計算ができないケースもあります。
整合性チェックも忘れてはなりません。型のバリデーションとして、分析前に自動的に型を推定する仕組みで各列の型をチェックし、想定した型になっているか確認します。そして、ドメイン知識を活用し、あり得ない値(年齢が300歳など)が混在していないか、部署名の誤字や全角/半角混在など、実務の文脈を踏まえた整合性を確認することも重要です。
一貫性のあるコーディングも重要です[5]。例えば「男性」を「M」「男」「Male」など複数の表記揺れがあると分析時に集約できず混乱を招きます。これを防ぐため、事前にルールを設定することが望ましいでしょう。人事データにおいて、入社日が「2022年4月1日」「2022/4/1」「2022-04-01」など様々な形式で入力されていると、時系列での分析が困難になります。部署名が「営業部」「営業」「Sales Dept.」など統一されていないと、部署別の集計結果が不正確になります。
脚注
[1] データ構造の議論については以前、当社セミナーでも取り上げ、レポートとして公開しています。
[2] 「各型(表全体)が1つの表(データセット)をなす」という原則は、異なる種類の観測単位を、表の同一セル内に混在させないことを意味します。ことを意味します。例えば、「従業員の基本情報」と「評価結果」などを一つの表にまとめると、データの意味や集計単位が曖昧になり、分析時に不要な前処理が増える原因となります。
[4] 実務上は、主キーを設定していても必ずしも一意性が保たれるとは限りません。データ入力時のミスやシステムの不具合などにより、重複や誤りが意図せず生じることがあります。これを防ぐには、主キーが本当に一意になっているかを定期的に検証し、必要に応じてデータの修正やクリーニング作業を行うことが求められます。
[5] 実務においては、データ構造そのものの課題に加え、組織変更や担当者間のスキル差、部署間での連携不足などが原因となり、データの一貫性や正確性が損なわれる場合があります。これらは分析精度の低下を招きかねないため、データの整理に留まらず、入力プロセスの標準化や組織を超えたコミュニケーションの改善、担当者への継続的な教育といった包括的な対応が必要となります。
執筆者
 伊達 洋駆 株式会社ビジネスリサーチラボ 代表取締役
伊達 洋駆 株式会社ビジネスリサーチラボ 代表取締役
神戸大学大学院経営学研究科 博士前期課程修了。修士(経営学)。2009年にLLPビジネスリサーチラボ、2011年に株式会社ビジネスリサーチラボを創業。以降、組織・人事領域を中心に、民間企業を対象にした調査・コンサルティング事業を展開。研究知と実践知の両方を活用した「アカデミックリサーチ」をコンセプトに、組織サーベイや人事データ分析のサービスを提供している。著書に『60分でわかる!心理的安全性 超入門』(技術評論社)や『現場でよくある課題への処方箋 人と組織の行動科学』(すばる舎)、『越境学習入門 組織を強くする「冒険人材」の育て方』(共著;日本能率協会マネジメントセンター)などがある。2022年に「日本の人事部 HRアワード2022」書籍部門 最優秀賞を受賞。東京大学大学院情報学環 特任研究員を兼務。




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}